05 ClickHouse Schema Evolution
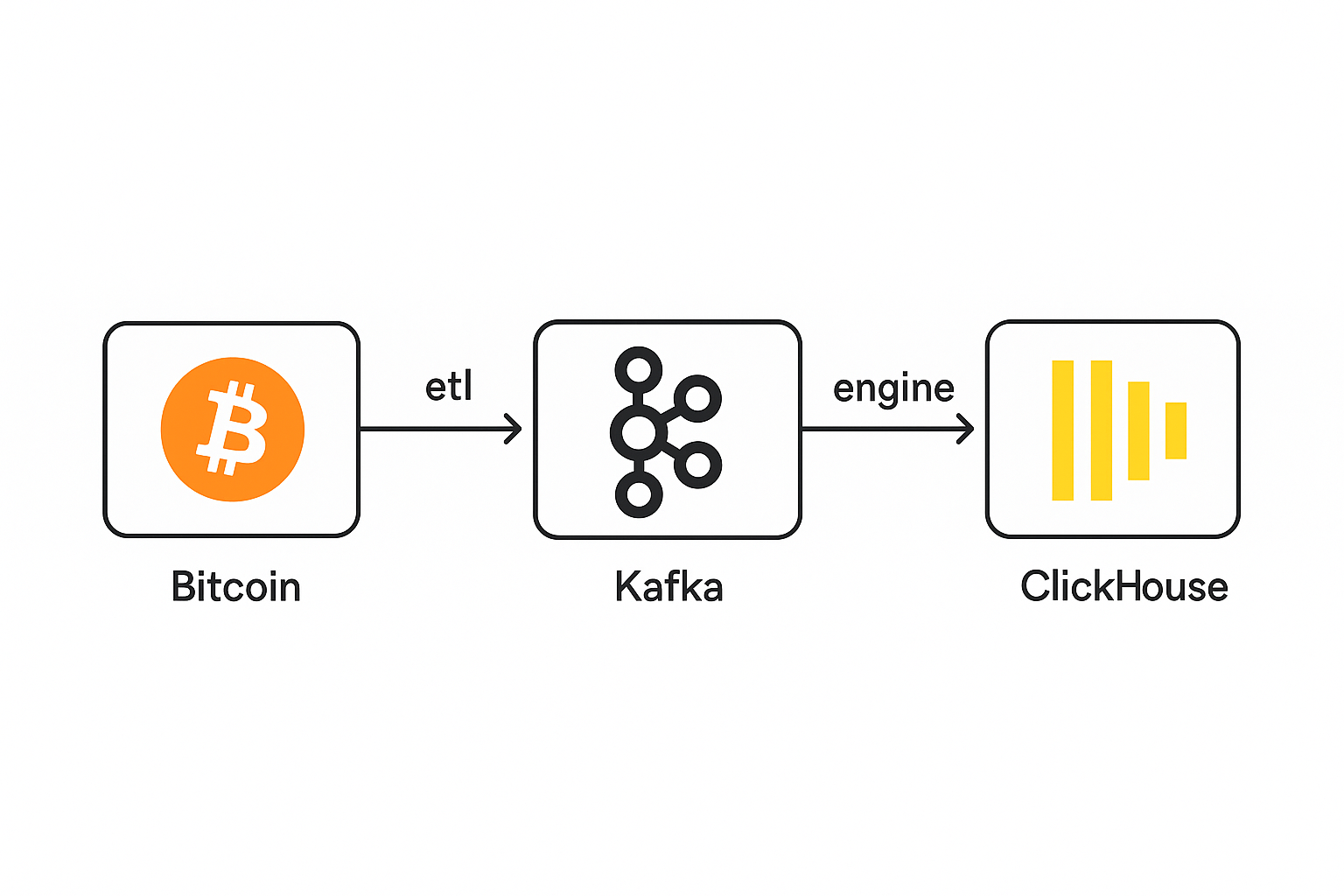
To add new attributes (previousblockhash, transactions, and nTx) to a ClickHouse table using the Kafka engine—assuming your existing table already receives streaming data from Kafka—you must follow a safe schema evolution process due to ClickHouse's strict handling of schemas and its decoupled ingestion setup. Here's a professional, step-by-step guide as if taught by a professor of ClickHouse + Kafka streaming integration.
| Layer | Action |
|---|---|
| Kafka Producer | Add the new fields to emitted JSON |
| Kafka Engine Table | ALTER TABLE blocks_queue ADD COLUMN |
| Materialized View | Drop and recreate blocks_mv with new SELECT clause |
| Destination Table | Add new fields using ALTER TABLE blocks ADD COLUMN |
| Verification | Use SELECT queries to validate parsing |
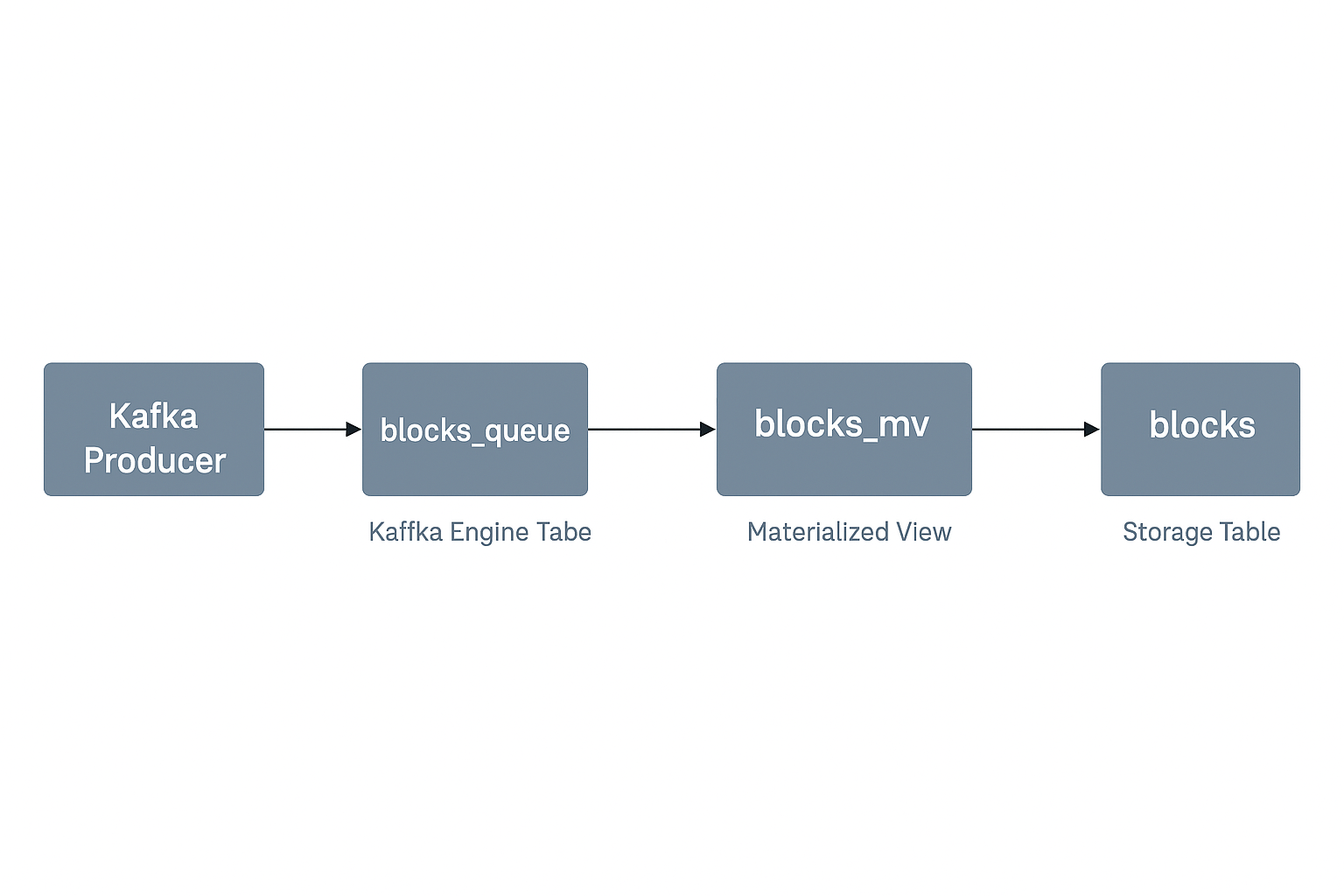
In production systems, graceful schema evolution means:
- Pausing ingestion
- Updating schema
- Restarting streaming with minimal data loss or duplication
Below is a professor-level, zero-downtime-friendly guide to safely modify a Kafka-to-ClickHouse pipeline using your components:
Kafka 1: Stop the Kafka Producer
Pause the source application producing data to the
blocksKafka topic to prevent in-flight writes while you upgrade schema.
# Stop the producer app or its Kafka client (Ctrl + C)
python3 bitcoinetl.py stream -p http://bitcoin:password@localhost:8332 --output kafka/localhost:9092 --period-seconds 0 -b 100 -B 1000 --log-file log --enrich True -l last_synced_block.txt
DETACH blocks_queue
Kafka 2: Add new Attributes in Producer(ETL)
Add previous_block_hash, difficulty and nTx. This commit mainly focuses on adding block-only streaming support, improving block metadata handling, and enhancing Kafka/ClickHouse integration and documentation.
Blocks 3: Create new Kafka Engine Table
CREATE TABLE blocks_queue_v1
(
hash String,
size UInt64,
stripped_size UInt64,
weight UInt64,
number UInt64,
version UInt64,
merkle_root String,
timestamp DateTime,
nonce String,
bits String,
coinbase_param String,
transaction_count UInt64,
previous_block_hash String,
difficulty Float64,
nTx UInt64,
transactions Array(String)
)
ENGINE = Kafka('localhost:9092', 'blocks', 'bitcoin-group', 'JSONEachRow') settings kafka_thread_per_consumer = 0, kafka_num_consumers = 3;
If unsure all messages will have these fields, use
Nullable(...).
Blocks 4: Create new MergeTree Table
CREATE TABLE blocks_fat
(
hash String,
size UInt64,
stripped_size UInt64,
weight UInt64,
number UInt64,
version UInt64,
merkle_root String,
timestamp DateTime,
timestamp_month Date,
nonce String,
bits String,
coinbase_param String,
transaction_count UInt64,
previous_block_hash String,
difficulty Float64,
nTx UInt64,
transactions Array(String)
)
ENGINE = ReplacingMergeTree()
PRIMARY KEY (hash)
PARTITION BY toYYYYMM(timestamp_month)
ORDER BY hash;
Blocks 5: Recreate the Materialized View
CREATE MATERIALIZED VIEW blocks_mv_v1 TO blocks_fat
AS
SELECT
*,
toStartOfMonth(timestamp) AS timestamp_month
FROM blocks_queue_v1;
Blocks 5: Create Materialized View
CREATE TABLE blocks ( hash String, size UInt64, stripped_size UInt64, weight UInt64, number UInt64, version UInt64, merkle_root String, timestamp DateTime, timestamp_month Date, nonce String, bits String, coinbase_param String, transaction_count UInt64, previous_block_hash String, difficulty Float64, nTx UInt64, ) ENGINE = MergeTree() PRIMARY KEY (hash) PARTITION BY toYYYYMM(timestamp_month) ORDER BY hash;
```sql
CREATE MATERIALIZED VIEW mv_blocks
TO blocks
AS
SELECT
hash,
size,
stripped_size,
weight,
number,
version,
merkle_root,
timestamp,
timestamp_month,
nonce,
bits,
coinbase_param,
transaction_count,
previous_block_hash,
difficulty,
nTx
FROM blocks_fat;
SET max_partitions_per_insert_block = 500;
Manual Backfill to blocks
INSERT INTO blocks
SELECT
hash,
size,
stripped_size,
weight,
number,
version,
merkle_root,
timestamp,
timestamp_month,
nonce,
bits,
coinbase_param,
transaction_count,
previous_block_hash,
difficulty,
nTx
FROM blocks_fat;
Tnx 1: Fat row include Array
CREATE TABLE transactions_fat
(
hash String,
size UInt64,
virtual_size UInt64,
version UInt64,
lock_time UInt64,
block_hash String,
block_number UInt64,
block_timestamp DateTime,
block_timestamp_month Date,
input_count UInt64,
output_count UInt64,
input_value Float64,
output_value Float64,
is_coinbase BOOL,
fee Float64,
inputs Array(Tuple(index UInt64, spent_transaction_hash String, spent_output_index UInt64, script_asm String, script_hex String, sequence UInt64, required_signatures UInt64, type String, addresses Array(String), value Float64)),
outputs Array(Tuple(index UInt64, script_asm String, script_hex String, required_signatures UInt64, type String, addresses Array(String), value Float64))
)
ENGINE = ReplacingMergeTree()
PRIMARY KEY (hash)
PARTITION BY toYYYYMM(block_timestamp_month)
ORDER BY (hash);
INSERT INTO transactions_fat (
hash, size, virtual_size, version, lock_time,
block_hash, block_number,
input_count, output_count,
input_value, output_value,
is_coinbase, fee,
inputs, outputs,
block_timestamp, block_timestamp_month
)
SELECT
hash, size, virtual_size, version, lock_time,
block_hash, block_number,
input_count, output_count,
input_value, output_value,
is_coinbase, fee,
inputs, outputs,
b.timestamp AS block_timestamp,
b.timestamp_month AS block_timestamp_month
FROM transactions_v1
INNER JOIN blocks AS b ON block_hash = b.hash;
SELECT
partition,
count()
FROM system.parts
WHERE table = 'transactions_fat'
AND active
GROUP BY partition
ORDER BY partition;
Step 6: Resume the Kafka Producer
Now that the pipeline is upgraded, restart the producer:
# Restart your Kafka producer
python3 bitcoinetl.py stream_block -p http://bitcoin:passw0rd@localhost:8332 --output kafka/localhost:9092 --period-seconds 0 -b 100 -B 500 --enrich false --start-block 0
Step 7: Validate End-to-End
SELECT
hash,
previousblockhash,
nTx,
length(transactions) AS tx_count
FROM blocks
ORDER BY height DESC
LIMIT 10;
Ensure everything flows correctly.